


From Synonyms to Object Properties
It’s well known that word embeddings are excellent for finding similarities between words — specifically, synonyms. We achieve this using supervised machine learning techniques by showing a neural net a dataset of hundreds of millions of pieces of text. The algorithm looks at the context and frequency in which particular words appear together, and maps them out as vectors in multi-dimensional space (or what we otherwise refer to as word embeddings).
A couple of weeks ago, our CTO Slater Victoroff gave a talk on “Using and abusing text embeddings” for the recent AI with the Best conference, where he presented an interesting — and surprising — finding. Not only do word embeddings successfully find synonyms, but also appear to pick up on object properties. For instance, “grass” and “green” seem to map closely to one another, as well as “ocean” and “blue”; “black” and “obsidian”; “sulfur” and “yellow”. These connections are surprising, given the broad range of contexts in the training dataset — we’d expect that the model could only gain this kind of information through rare events like metaphors and analogies. It’s intriguing that the algorithm still managed to learn and represent these relationships, but it’s not clear to us how or why these connections were learned, or how they’re represented in the underlying neural network.
From a utilization perspective, however, we don’t necessarily need to understand that structure. If these general embeddings can actually pick up on object properties or definitions as “weak synonyms” (and it’s not just an odd statistical anomaly), we expect that retraining our embeddings with domain specificity should deliver a similar result for those industry-focused cases. We could then use them to build a more robust fuzzy search tool or chatbots for specific industries.
So, let’s test our hypothesis. As part of his presentation, Slater wrote a script that allows you to play Twenty Questions with your machine using indico’s general text feature embeddings. Let’s tweak it to work with our finance-specific text embeddings. (Or, skip ahead to the Results section.)
Updating the Code
There are only a few pieces of the code that we need to change here. Instead of importing the NOUNS library, we’ll just add a small list of financial terms to the featurize_nouns function.
finance_nouns = ["accounts payable", "accounts receivable", "accrual basis", "amortization", "arbitrage", "asset", "bankruptcy", "bond", "boom", "capital", "cash basis", "certificate of deposit", "commodity", "cost of capital", "cumulative", "debt", "deficit", "depreciation", "dividend", "economy", "equity", "exchange traded fund", "fiduciary", "fund", "gross domestic product", "growth stock", "hedge fund", "internal revenue", "intrinsic", "invest", "invoice", "leverage", "liability", "margin account", "margin call", "money market", "mortgage", "mutual fund", "paycheck", "portfolio", "premium", "profit", "real estate", "recession", "return", "revenue", "savings", "short selling", "stock", "trade", "Treasury bill", "treasury stock", "value", "volatility", "wager" ]
Underneath that, specify that you want to use indico’s finance feature embeddings by updating vectorize for the features variable.
features = vectorize(finance_nouns, domain="finance", batch_size=200)
You will need to do the same for the answer_features variable in the ask_question function.
answer_features = vectorize(options[int(response)], domain="finance")
Aaaand once again in the closest_difference function.
features = vectorize(list(args), domain="finance")
Now, change all instances of NOUNS across the script to finance_nouns.
You’re almost there! The last thing to change are the keywords you want to use as part of the twenty questions that the program should ask. These are the keywords we used:
twenty_questions([
["macro", "micro"],
["accounting", "investing", "economics"],
["gain", "loss"]
])
Results
When we run the program, we can see that the embeddings do pick up on “object properties” for these more abstract finance domain-specific terms. For instance, selecting “accounting”, “macro”, and “gain” results in the following guesses: internal revenue, asset, accounts receivable, margin account, and revenue.
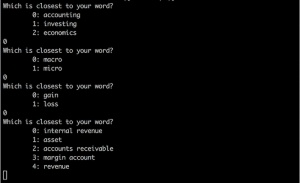
Note that our embeddings were trained on quarterly financial reports, which is why they perform better for accounting terminology versus investing and economics concepts. It’s fairly easy to update the embeddings to deal better with investing and economics nomenclature, though. Using Custom Collection and CrowdLabel, you can customize indico’s finance embeddings by retraining them with labeled investment documents to better suit the task at hand.
Once trained, the embeddings can be implemented in fuzzy search tools, FAQs bots, and numerous other applications. If you need help with training or want to learn more, feel free to reach out at contact@indico.io!