


Spans are an innovation from the Indico Data team that enables your workflows to live up to their fullest potential. Though things may not look different on your end, spans are the first step in a major transformation for the Indico platform and its users.
What are spans?
Spans are a new way of representing data in the Indico platform that standardizes model input and output. Spans are the first step in enabling users to use Indico’s basic building blocks to create workflows so new and innovative that we’ve never even dared to dream them up! They are the key to making way for new highly requested features, model combinations, and more.
But what actually are spans? Spans are representations of data at a sub-document level. Or, less technically, instead of viewing a whole document, spans enable our models to break up a document into smaller pieces of data. Before spans, our models followed a rigid set of rules regarding representing data. With spans, models have the ability to break up data into different-sized portions, enabling a world of features and making our platform even more powerful. A unit of data can now be an extraction label, an image, or countless other options. And spans enable all this while keeping the context of the original document, making it easier for humans to understand too. This truly is the stuff of fantasy!
What problems do spans solve?
Previously, Indico’s models were overparticular – each model wanted its data and training labels to be structured in a specific way (encoded text vs. raw files, strings vs. lists of dictionaries, etc.). The most significant limitations for us, and you, our users, were:
- Complex integration of new models into the Indico platform
- An inability to connect certain model types in a workflow. You’ve felt it. We’ve felt it. You can’t connect models – Classifying extracted clauses from legal documents, extracting an address, and then breaking it up into address components with another extraction model (street, street number, city, zip, state, etc.) or many other useful combinations are not currently possible in our app. The reason was that these particular I/O requirements for our models would require long, brittle code to try and combine.
In addition, the platform was designed so training labels and model predictions always received the entire input file as input. So what happens when users want to process files that are hundreds of pages long but only actually care about the header page for classification? When models thrive on learning from specific and relevant data, giving a model a bunch of extra information can drastically reduce performance. Up until now, there was no way on the platform to “narrow the focus.”
Finally, labeling non-continuous data was previously impossible. For text extraction models, a label needed to apply to a continuous range of characters. For image extraction models, a label needed to apply to a single bounding box. But the data we work with is unstructured and there’s no guarantee that the single item you want to extract appears together all the time.
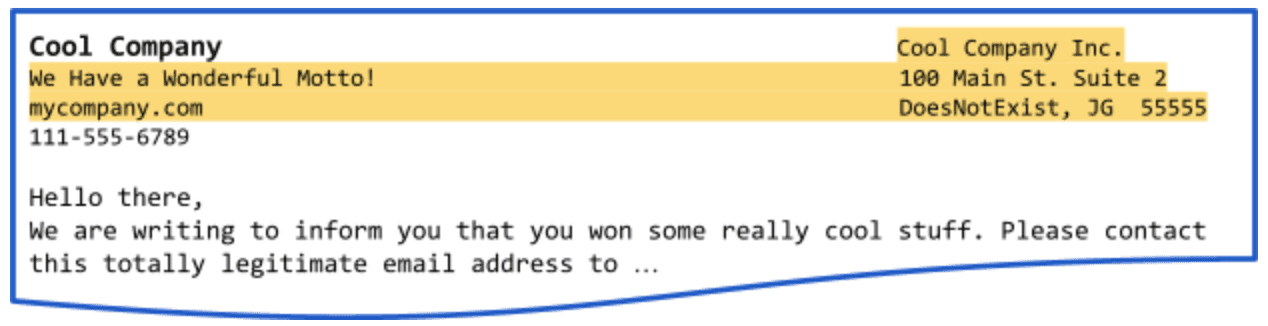
Take this simple example – we want to extract the entire address from this document. Simple left-to-right highlighting would not only capture the address but also the company motto and website that appears on the left.
To get around this, you’d need to make individual labels for each address line and join in post-processing – an annoying process that adds extra steps to your workflow. Label spans solve this problem by redefining how we capture portions of data to account for the myriad circumstances our app encounters.
How are spans solving this problem?
Spans (or as we refer to them as a unit, a Span-Group) is a fancy word to describe a “portion of data.” It’s an object which has an underlying reference to the original source of data it came from, and a representation for a portion of the original source.
A “text” span-group is represented by a list of start/end/pageNum character ranges in the source text.
| Document
– – Page 1 – – Hello my name is Foo – – Page 2 – – This is my friend Bar |
Representative Span-Group
[ { start: 0, end: 19, page_num: 0 }, { start: 21, end: 41, page_num: 1 } ] |
An image span-group is represented by a list of top/bottom/left/right/pageNum bounding boxes on the source image.
| Image
|
Representative Span-Group
[ { top: 0, bottom: 100, left: 0, right: 100, page_num: 0 } ] |

In the platform with spans, all data is represented as Span-Groups – gone are the days of “sometimes files and sometimes URLs and sometimes raw text and sometimes feature vectors.” Additionally, a SpanGroup can be interpreted as any model needs! The SpanGroup for a text document can be converted to a bounding-box SpanGroup by simply referencing the source file, and vice-versa.
The biggest perk is that models can generate spans as well! Consider an extraction model – it extracts a portion of a document or image – an extraction label is simply a set of “class name and SpanGroup.” In our above example for Document, an extraction model that predicted “Person Name” would do the following
Document -> SpanGroup -> Prediction
Prediction (as you might know it today)
[
{label: “Person Name”, start: 17, end, 19, text: “Foo”},
{label: “Person Name”, start: 39, end: 41, text: “Bar”}
]
Using the same SpanGroup data structure as before, each extraction becomes its own SpanGroup!
Prediction w/ SpanGroups
[
{label: “Person Name”, spans: [{start: 17, end: 19, page_num: 0}]},
{label: “Person Name”, spans: [{start: 39, end: 41, page_num: 1}]}
]
Readers with a keen eye might wonder – why are these “nested” – why does each extraction.spans become a list instead of a single start-end? Excellent question! This will allow us to handle non-continuous extractions. Using the same label-the-address question as before, we could now accurately label and predict the address on the document.

Address Label
{
label: “Address”,
spans: [
{start: 12, end: 16, page_num: 0},
{start: 43, end: 63, page_num: 0},
{start: 78, end: 98, page_num: 0}
]
}
Ultimately, this means labels or predictions from models can themselves be used as sources of data for downstream models. Finally, we have a way of seamlessly connecting any model to any other model.
As a bonus, a SpanGroup always references its original source data. This means for labelers, there’s always going to be an ability to look at the entire image or file, even if the model you’re labeling for only cares about some specific SpanGroup on that file. We want to help our users narrow the focus of their models but still give them the flexibility to see and understand all their data.
Conclusion
If you’re saying to yourself, “this is incredible! When can I start using these?” we have some excellent news for you! The wait won’t be long – spans are coming to the Indico platform in our upcoming 5.1 release which is set for April of 2022.
We are excited about these improvements and the great benefits our customers will realize with them. We hope you are too!