


Thank you for being a valued Indico user. The Indico Data team is excited to launch 5.1, the newest addition to our ever-evolving platform. We strive to provide a best-in-class application, and 5.1 introduces highly requested and transformational functionality that allows our users to accelerate their workflows further. These release notes are home to all release documentation regarding 5.1, including our patch release notes. Find the breaking changes documentation for this release on our knowledge base.
Innovations and Updates in v5.1
 Unbundling your files with Document Unbundling
Unbundling your files with Document Unbundling
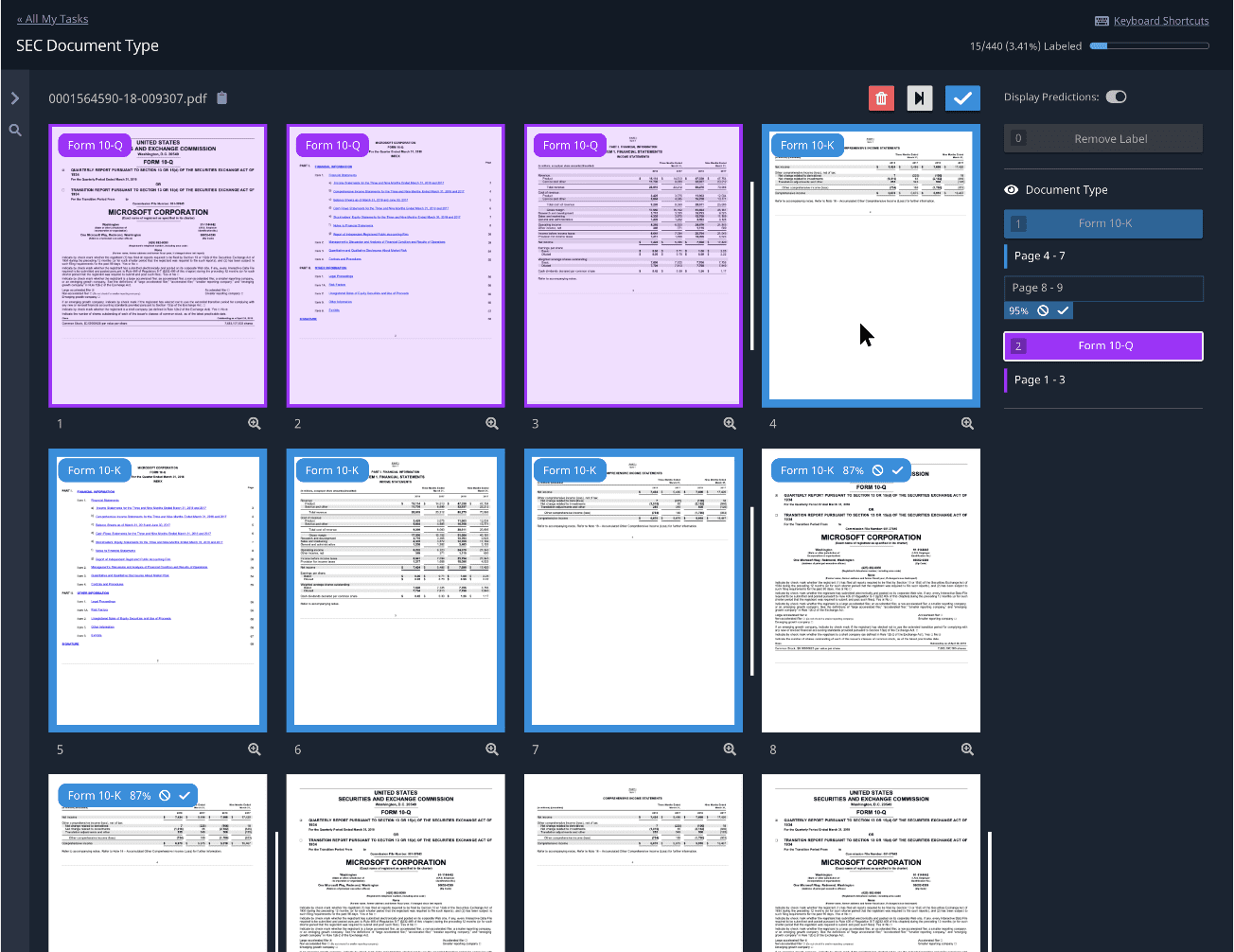
- It’s finally here! The feature long fantasized about by Indico users – document unbundling.
- Document unbundling allows you to classify the documents in a file by document types. This new feature eliminates the necessity for manual separating and re-uploading by allowing you to split the document right in the Indico platform!
- The fun doesn’t stop there. In addition to simplifying unbundling, this feature lets you keep the original context of the document, making labeling and other processing more straightforward and accurate.
- Find out more about this fantastic feature in Indico’s knowledge base.
- Introducing Label Spans!
- 5.1 delivers an invisible change to the platform: label spans! While you may not be able to see the difference in how the platform is operating, label spans are setting the groundwork for incredible features coming out later this year.
- Read more about the what, how, and why of label spans in our blog post.
 API/SDK Updates
API/SDK Updates
- The SDK call AddDataToWorkflow with CSV datasets has been improved for 5.0 and beyond.
- Some of our other SDK calls have been updated in this version to adapt to the changes to the Workflows module.
- Some GraphQL calls have been updated to new, snazzier versions.
- The SDK call AddDataToWorkflow with CSV datasets has been improved for 5.0 and beyond.
- Other Improvements
- In specific situations, Workflows “try it out” was returning an error. This has been corrected in this release.
- This update features a Finetune upgrade and new feature enablement.
- Improvements to PNG and JPG image processing in Teach have been implemented to reduce pixelation.
- Snapshots have changed! Snapshots now contain information like example_id and page_num. Now that’s a snappy update!
- Workflows now uses the dataset’s default_datacolumn_id as the source of data for all new and existing workflows. In a text document CSV, the first “string“ column that isn’t labels will be selected as the default datacolumn.
- You cannot modify workflows (with AddData or AddComponent) or retrain models that do not use the dataset’s default datacolumn.
- You must use the dataset’s default datacolumn to create workflows or workflow components.
Patch Releases For This Version:
-
Updates in 5.1.1
- In the Workflows module, examples are now sorted according to the criteria selected from the Sort By drop-down. Examples appear in the examples table accordingly.
- Label reordering has been improved to save changes after manual reordering.
- After Unbundling models, models in a workflow can no longer use prelabeled data.
- Improvements have been made to CSV uploading technology to ensure no duplications.
- Previously, after turning off predictions for Unbundling models, predictions would still appear in the labeling interface. This has been corrected.
- For extraction models that are downstream from Unbundling models, for any unlabeled examples, predictions are now shown on each page.
- List of Datasets on Workflows now appears in reverse chronological order (with the most recent at the top).
- Tasks downstream from unbundling models now have their examples updated when AddData is called.
- Custom workflow scripts are now functioning for 5.1.
- Snapshot generation improvements from Explain and Teach pages.
-
Updates in 5.1.2
- In a specific circumstance, users were restricted from adding models to a workflow via the Workflows canvas. This has been corrected.
- Labelers can now access their tasks and apply labels without encountering an example loading error.
- Previously, certain tasks in 5.1 failed to load. This has been corrected.
- This patch corrects an issue causing pre-labeled object detection models to remain stuck in training after being added to a workflow.
- This patch contains a fix for ReadAPI failing in certain instances.